Abstract
Imagining the future trajectory is the key for robots to make sound planning and successfully reach their goals. Therefore, text-conditioned video prediction (TVP) is an essential task to facilitate general robot policy learning, i.e., predicting future video frames with a given language instruction and reference frames. It is a highly challenging task to ground task-level goals specified by instructions and high-fidelity frames together, requiring large-scale data and computation. To tackle this task and empower robots with the ability to foresee the future, we propose a sample and computation-efficient model, named Seer, by inflating the pretrained text-to-image (T2I) stable diffusion models along the temporal axis. We inflate the denoising U-Net and language conditioning model with two novel techniques, Autoregressive Spatial-Temporal Attention and Frame Sequential Text Decomposer, to propagate the rich prior knowledge in the pretrained T2I models across the frames. With the well-designed architecture, Seer makes it possible to generate high-fidelity, coherent, and instruction-aligned video frames by fine-tuning a few layers on a small amount of data. The experimental results on Something Something V2 (SSv2) and Bridgedata datasets demonstrate our superior video prediction performance with around 210-hour training on 4 RTX 3090 GPUs: decreasing the FVD of the current SOTA model from 290 to 200 on SSv2 and achieving at least 70% preference in the human evaluation.
Method
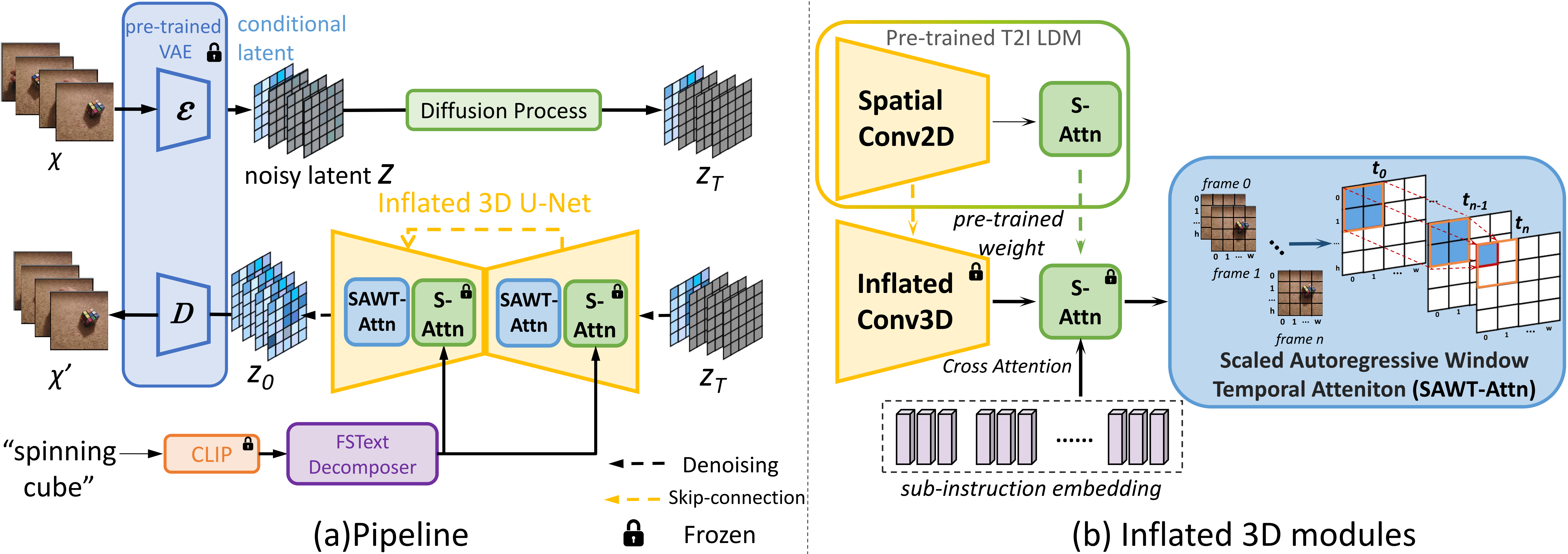
Seer's pipeline includes an Inflated 3D U-Net for diffusion and a Frame Sequential Text Transformer (FSeq Text Transformer) for text conditioning. During training, all video frames are compressed to latent space with a pre-trained VAE encoder. Conditional latent vectors, sampled from reference video frames (ref.), are concatenated with noisy latent vectors along the frame axis to form the input latent. During inference, the conditional latent vectors are concatenated with Gaussian noise vectors, text conditioning is injected for each frame by FSeq Text Transformer (e.g., global instruction embedding “Moving remote and small remote away from each other.” is decomposed into 12 frames sub-instructions along the frame axis), and the denoised outputs are decoded to RGB video frames with the pre-trained VAE decoder.
Results
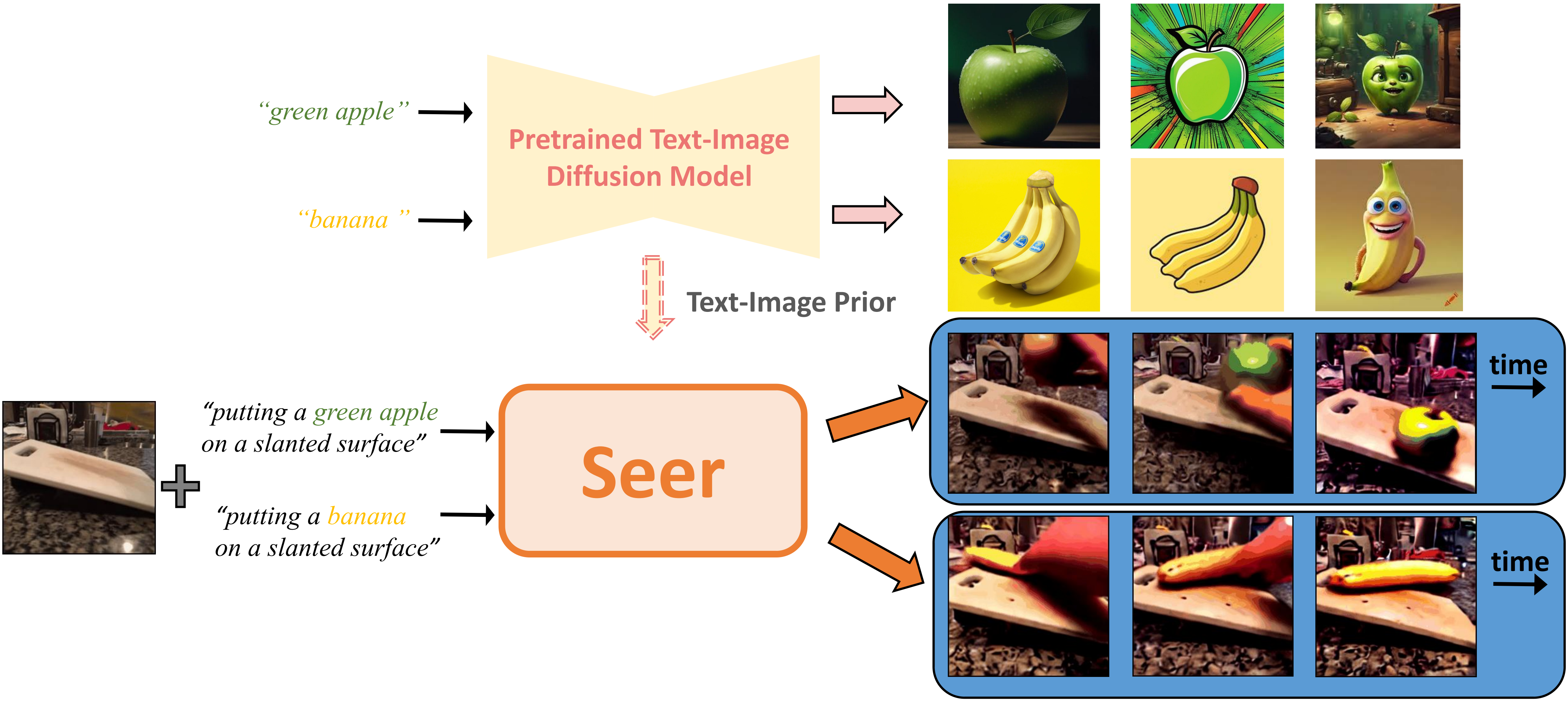
Text-conditioned Video Prediction/Manipulation
(Something-Something V2 Dataset)

























Text-conditioned Video Prediction/Manipulation (BridgeData)

















Text-conditioned Video Prediction (Epic-Kitchens)











Bibtex